이 글을 쓰게된 이유는
회사 업무로 망분리 환경에서 데이터 파이프라인을 구축하는 업무를 하게되었다.
td-agent (fluentd 래핑된 프로그램)으로 Hadoop HDFS에 access log를 저장하는 데이터 파이프라인 구축 업무였고,
구축하는 과정에서 발생한 문제와 왜 발생했는지 해결 내용을 공유하기 위해 작성했다.
망분리 환경에서 td-agent(fluentd) <-> HDFS 간 파이프라인 설정할 때, 도움이 되었으면한다.!
대충 환경은 이러했다.
td-agent 서버(물리) <-> HDFS (물리) 간에 방화벽 정책으로 인해 allow 정책이 있지 않는 상태이며, all deny 상태.
자.. 파이프라인을 구축하는 과정에서 어떤 문제가 있었는지 먼저 설명하겠다.
fluentd의 webhdfs 외부 플러그인을 사용하게 되면, 아래와 같이 config를 설정하게 될 것이다.
(아래 설정 내용은 https://github.com/fluent/fluent-plugin-webhdfs의 README에 있는 내용을 예시로 가져옴)
<match access.**>
@type webhdfs
host namenode.your.cluster.local
port 50070
path "/log/access/%Y%m%d/#{Socket.gethostname}.log" # double quotes needed to expand ruby expression in string
</match>[참고] fluentd webhdfs 플러그인?
- Ruby 언어로 만들어졌으며, hadoop hdfs에 data를 저장하기 위한 fluentd의 플러그인
- https://docs.fluentd.org/output/webhdfs
config 구성을 보면, namenode hostname을 입력하고, port를 입력하는 것을 볼 수 있다.
그래서 나는 방화벽 port 오픈도 namenode로 통신 가능하게끔만 인프라팀에 오픈 요청을 했다.
- 방화벽 요청 내용
src = td-agent 서버
dst = namenode:50070
그랬더니 무슨 일이 벌어졌냐?
td-agent log에서 뜬금없이 DataNode:50075에 통신할 수 없다는 에러가 발생하기 시작했다.
??? 로그를 보고 왜 DataNode로 연결을 시도하는지 이해하지 못했다. DataNode도 열어줘야하나?
왜 열어줘야하지? 찾기 시작했다.
이게 내가 이글을 작성하게 된 이유다.
왜 DataNode:50075 방화벽 정책을 열어줘야 했을까?
상세 동작을 설명하기 이전에 핵심내용부터 얘기하자면,
내가 놓치고 있는 부분이 있었다.
td-agent에서 HDFS로 file을 write하는 것은, HDFS에 file write 하는 과정이랑 동일하다는 것이다.
즉, HDFS에 file write 하는 과정에서 NameNode의 역할, DataNode의 역할을 생각하면 된다.
NameNode는 메타정보만 저장할 뿐, 실질적으로 file(block)이 저장되는 곳은 DataNode라는 거다.
아래 그림을 보면 좀 더 이해하는데 도움이 될 것이다.
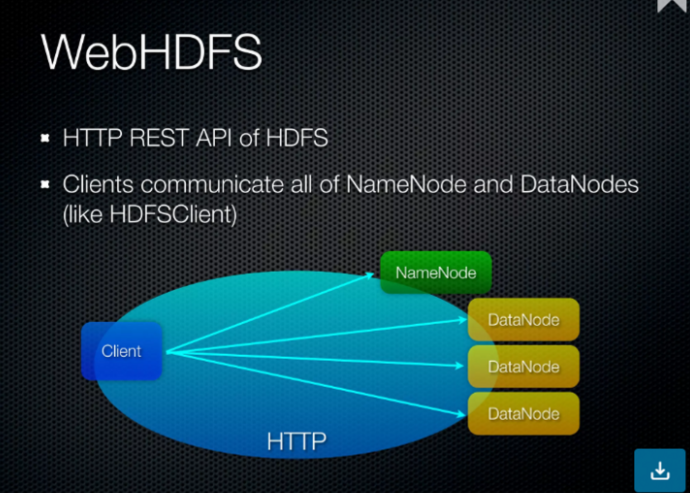
지금부터, 어떻게 td-agent의 webhdfs 플러그인에서 file write가 동작하고 있는지,
오픈소스를 뒤져가며 확인한 내용들을 세부적으로 설명하겠다.
일단 설명하기 앞서, 나는 Ruby를 하나도 모른다.. 그냥 하나의 프로그래밍 언어니까 흐름만 대충 봤다.
(문법만 다르지 뭐.. 흐름은 비슷하겠지~ 라는생각으로)
ruby로 개발된 fluentd의 webhdfs 플러그인 github 주소는 여기다.
GitHub - fluent/fluent-plugin-webhdfs: Hadoop WebHDFS output plugin for Fluentd
Hadoop WebHDFS output plugin for Fluentd. Contribute to fluent/fluent-plugin-webhdfs development by creating an account on GitHub.
github.com
ruby 코드 구성이 어떻게 되는지 모르다보니, 오픈소스를 전체적으로 먼저 훑어봤다.
그러다보니 webhdfs 플러그인에서 hdfs로 file write 하는 것처럼 보이는 부분이 보였다.
`write` 함수 부분인데, 해당 함수를 쭉 보다보면 `send_data`라는 함수를 호출하는 것을 볼 수 있다.
`send_data` 함수의 일부를 가져온건데, 보면 @client라는 객체로 보이는 것의 create 함수를 호출하는 것을 볼 수 있다.
def send_data(path, data)
return @client.create(path, data, {'overwrite' => 'true'}) unless @append이 @client라는 객체가 어떻게 인스턴스화 되는지 확인했다.
`configure` 함수에서 `prepare_client` 함수를 통해 생성되는 것을 볼 수 있다.
그럼 `prepare_client` 함수는 또 뭐냐.. 들여다보니, 아래 처럼 WebHDFS::Client.new 부분이 있었다.
보자마자 c++처럼 webHDFS는 라이브러리겠구나라는 생각이 들었고, 맞았다.
def prepare_client(host, port, username)
client = WebHDFS::Client.new(host, port, username, nil, nil, nil, {}, @renew_kerberos_delegation_token_interval_hour)선언되고 있는 부분
require 'webhdfs'오픈소스 파일을 보면, python의 requirements처럼 라이브러리 선언되어있는 파일이 있었으며, 아래처럼 작성 되어있는 것을 볼 수 있다.
https://github.com/fluent/fluent-plugin-webhdfs/blob/master/fluent-plugin-webhdfs.gemspec
gem.add_runtime_dependency "webhdfs", '>= 0.10.0'
그럼 이제 저 ruby webhdfs 라이브러리가 어떻게 구성되어있는지 들어가봤다.
GitHub - kzk/webhdfs: Ruby client for Hadoop WebHDFS
Ruby client for Hadoop WebHDFS. Contribute to kzk/webhdfs development by creating an account on GitHub.
github.com
ruby webhdfs 라이브러리 오픈소스를 보다보니, create 부분을 찾을 수 있었다.
이게 create 함수 부분인데, 주석 미쳤다. 감사합니다.
# curl -i -X PUT "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=CREATE
# [&overwrite=<true|false>][&blocksize=<LONG>][&replication=<SHORT>]
# [&permission=<OCTAL>][&buffersize=<INT>]
# [&delegation=<DELEGATION_TOKEN>]"
def create(path, body, options={})
if @httpfs_mode
options = options.merge({'data' => 'true'})
end
if @renew_kerberos_delegation_token_time_hour
options = options.merge('delegation' => get_cached_kerberos_delegation_token)
end
check_options(options, OPT_TABLE['CREATE'])
res = operate_requests('PUT', path, 'CREATE', options, body)
res.code == '201'
end
OPT_TABLE['CREATE'] = ['overwrite', 'blocksize', 'replication', 'permission', 'buffersize', 'data', 'delegation']
바로 apache hadoop WebHDFS REST API를 검색했다.
https://hadoop.apache.org/docs/r1.0.4/webhdfs.html#CREATE
여기에 왜 DataNode의 Hostname이 redirection 되는지에 대한 이유가 있었다.
위에 내용을 읽어보면,
CREATE API는 request로 NameNode의 정보를 받고, DataNode로 redirection 되는 것을 볼 수 있었다.

이렇게 왜 DataNode:50075를 망분리 환경에서 추가로 방화벽 오픈해줘야하는지 이유를 명확하게 알게되었다.
이유를 알고나니, 하나 더 궁금한게 있었다.
어떻게? hostname으로 redirection 하지??
stackoverflow에 똑같은 질문이 있었다. ㅎ
hdfs-site.xml 설정파일에서 `dfs.datanode.hostname` 부분에 정의된 Value에 따라 webhdfs는 반환한다고 한다.
Returning ip address instead of hostname in webhdfs
I am trying to get files from hadoop using webhdfs, now the webhdfs is redirecting me to the datanodes. Its returning the hostnames in address , is there a way where we can make it return ip address
stackoverflow.com
오픈소스를 쭉 보다가 추가적으로 알게된 부분
td-agent의 webhdfs 플러그인에서 conf 파일에 NameNode 정보를 기입하게 되는데,
이 NameNode가 사용가능한 NameNode인지 확인하는 과정으로
apache hadoop WebHDFS의 LISTSTATUS API를 호출하여,
파일-디렉토리 메타정보를 수신함으로써 동작하고 있다는 것을 체크 한다는 것도 알게되었다.
https://hadoop.apache.org/docs/r1.0.4/webhdfs.html#LISTSTATUS
'Tech > Hadoop' 카테고리의 다른 글
| naver deview 영상 목록 (0) | 2022.11.06 |
|---|---|
| [Hadoop] hadoop 3.3.3 버전 docker로 설치하기 (0) | 2022.06.22 |
| [Hadoop]Docker Base 하둡 설치기 (2) (0) | 2022.03.20 |
| [Hadoop] Docker Data Node 추가, 삭제 (0) | 2022.03.11 |
| [Hadoop]core-site.xml, hdfs-site.xml (0) | 2022.03.11 |
