Airflow를 왜 사용하는가?

이처럼 데이터를 목적에 맞게 활용하기 위해서는
수집 → 처리 → 저장 절차를 거칠 것이다.
처리는 데이터가 수집이 되어야 가능하고, 저장은 저장할 처리된 데이터가 있어야 가능하다.
만약 여기서 데이터 수집에서 문제가 발생한다면?
처리 → 저장 과정은 진행되지 못 할 것이다.
단순히 하나의 데이터 파이프라인이라면, 장애를 파악하기 비교적 편할 것이다.
하지만 하나의 파이프라인이 아닌, x개의 데이터 파이프라인이 존재한다면?

데이터 파이프라인 개수가 많을 수록 장애 확인 및 처리에 시간이 많이 소요 될 것이다.
Airflow를 활용한다면, 데이터 파이프라인이 많더라도,
데이터 파이프라인을 시각적 관리, 모니터링, 스케쥴링, 데이터 파이프라인 설정 등을 관리하기 편이하다.
그럼 어떻게 Airflow로 많은 데이터 파이프라인을 효율적으로 관리를 하느냐? 궁금하다!.
Airflow의 동작 방식을 보자.
Airflow는 크게 5가지의 구성으로 볼 수 있다.
웹 서버, 스케줄러, 익스큐터, 메타스토어, 큐 이다.
웹 서버: 데이터를 표시하기 위해 메타스토어에서 데이터를 가져온다. (DAG, User Interface, User information etc...)
스케쥴러: 메타스토어의 DAG 정보를 기반으로 익스큐터에게 작업 실행을 요청한다.
익스큐터: 스케쥴러로부터 전달받은 작업을 실행하기 위해 큐에 전달하고 실행한다. 그 후, 메타스토어에 작업 상태를 업데이트한다.
메타스토어: 웹서버, 스케줄러, 익스큐터와 상호작용하며, 작업에 필요한 정보들을 저장하고 있으며, Airflow에서 가장 중요한 부분이다.
큐: 익스큐터가 작업을 순차적으로 실행 할 수 있도록 해준다. (ex. Redis, Rabbit MQ)
위 그림은 한 서버에서 Airflow를 구축했을 때 경우이다. (ex.로컬 구축)
실제 Production 레벨에서는 서비스들이 한 서버 안에 떠있지 않을 경우가 많다.(ex. MSA)
그럼 Airflow도 각 데이터 수집, 처리, 저장 서비스가 있는 서버에 분산되어 구축이 되어야하는데, 이때는 Python의 Celery(분산 비동기처리 라이브러리) 컨셉을 따라간다.
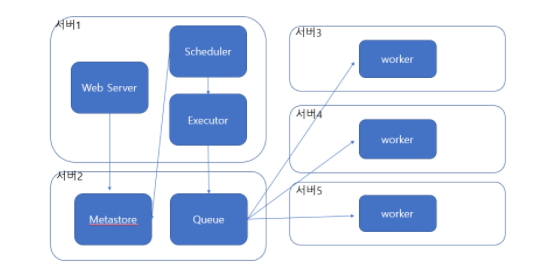
단일 서버 구성과 다른 점이라면,
워커가 각 서버에 위치하여 큐에서 데이터를 가져가 작업을 실행한다는 점이다.
(각 서버에 위치한 워커들은 Queue(Redis, RabbitMQ)에서 작업을 가져가고 수행하는 구조이다.)
방금까지는 Airflow가 어떻게 구성되는지 봤으니, 좀 더 세부적으로 Airflow가 어떻게 동작하는지 알아보자.

웹 서버와 스케줄러는 유저가 추가한 DAG File을 파싱한다.
스케줄러는 DAG File을 읽어, 메타스토어에 DAG Run Object를 생성하고, DAG의 내용을 TaskInstance Object로 생성한다.
익스큐터는 TaskInstance를 받아 실행하고, 완료시, TaskInstance를 완료상태로 업데이트 한다.
스케줄러는 해당 Task가 실행되고 완료되었는지 확인하고, 이 과정을 DAG 파일에 선언된 마지막 작업까지 계속해서 반복한다.
웹서버는 메타스토어에 저장된 데이터로 사용자 인터페이스를 업데이트한다.
(참고)
웹 서버와 스케줄러가 DAG File 파싱한다고 했는데,
파싱 주기는 설정할 수 있다.
DAG File 파싱 주기는 1초마다 이다. 관련 설정은 min_file_process_interval이다.
DAG File이 새로 추가되었는지 확인하는 주기는 기본 5분 주기 설정이다. 관련 설정은 dag_dir_list_interval이다.
워커들이 작업(batch)을 refresh하기 위한 기본 주기는 30초이다. 관련 설정은 worker_refresh_interval이다.
즉, 새로 DAG File을 추가하는 경우는 기본설정으로 5분을 기다려야 하며, 수정을하는 경우는 30초를 기다려야한다.
'Tech > Airflow' 카테고리의 다른 글
| [Airflow] ValueError: unsupported pickle protocol: 5 (1) | 2022.12.13 |
|---|---|
| Airflow 멀티테넌시 환경 구축하기 (2) | 2022.10.09 |
| [Airflow] catchup, depends_on_past, wait_for_downstream (0) | 2022.05.08 |
| [Airflow] Airflow 학습(3) (0) | 2022.05.01 |
| [Airflow] Airflow 학습 (2) (0) | 2022.04.26 |



